The "jump threading" compiler optimization (aka -fthread-jump) turns conditional into unconditional branches on certain paths at the expense of code size. For hardware with branch prediction, speculative execution, and prefetching, this can greatly improve performance. However, there is no scientific publication or documentation at all. The Wikipedia article is very short and incomplete. Here is a more comprehensive description.
Here is a simple example of the transformation. It shows a control flow graph were code in some basic blocks is shown.
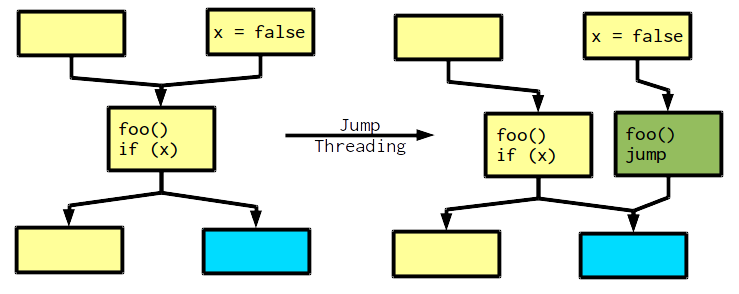
The central basic block contains a conditional jump (if). If the block is reached from the right side, x is false and we always branch into the blue block. Hence,jump threading rewires the control flow, to circumvent the if (the green block). However, the central block contains more code (the call to foo), which must be duplicated on the new path. If control flow comes from the left, we do not know x and if it continues to the blue block or not, thus the conditional jump must be preserved.
Jump threading can be more complex if loops are involved. The following example illustrates that.
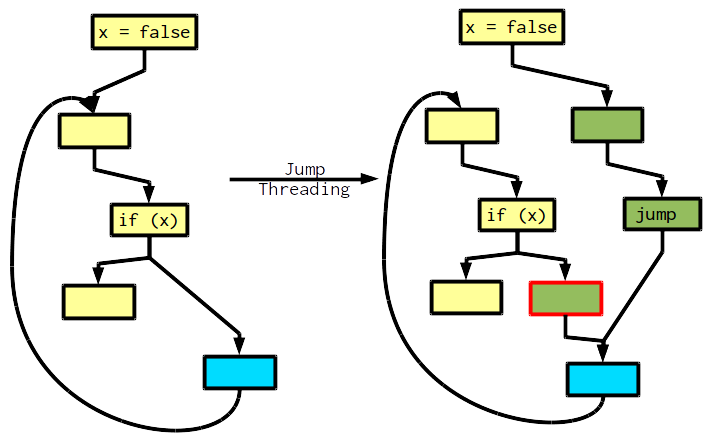
While the if has only one control flow predecessor, there is actually two paths we must consider: Loop entry and loop body. In the first iteration, coming from loop entry, we always take the false branch. The transformation duplicates the loop body of the first iteration and then goes into a loop. At this point we see that x did not change during the iteration and we can do a second transformation. Effectively, we perform loop peeling.
Also, note the block with the red border. It was inserted to not create a critical edge. This is usually desired during optimization.
In this example, we have an infinite loop, but you can easily change that. Nevertheless, it demonstrates a pitfall for compiler writers: An iterative approach is necessary, because one transformation might enable another one, which was not possible before. You have to guarantee termination somehow, though. I'm confident termination here can be very directly mapped to solving the halting problem.
Fortunately, Joachim Priesner stepped up to the problem and solved it gracefully. He defines the term "threading opportunity": a path through the control flow graph, which could be duplicated via jump threading. Having such a general formal definition, allows to compare different implementations.
LLVM
LLVM is restricted to threading opportunities of length 3. It uses the iterative approach described above, but without the termination issue, because it is so conservative.
GCC
GCC uses the analyse-then-transform approach. The analysis ignores threading opportunities, where branching control flow would have to be duplicated. It also makes sure not to create irreducible control flow, because later optimizations cannot handle that well.
libFirm 1.22
This is the current implementation, which is described above, until we merge Joachim's code. It uses the iterative approach. Like GCC, it does not duplicate branching control flow.
libFirm with Joachim's code
Once merged, libFirm uses the analyse-then-transform approach. The only restriction is that it limits the length of threading opportunities during analysis, because benchmarks showed a slowdown at some point. Jump threading inherently increases code size and with loops there might be a practically infinite number of threading opportunities.